
Claude Opus 4.5를 소개합니다
Claude Opus 4.5는 코딩과 업무 전반에서 세계 최고 수준의 성능을 갖춘 지능적이고 효율적인 차세대 AI 모델입니다.

- 원문 읽기: https://www.anthropic.com/news/claude-opus-4-5
- 카테고리: 뉴스
- 게시일: 2025년 11월 25일
오늘, 우리의 최신 모델인 Claude Opus 4.5를 출시합니다. 이 모델은 지능적이고 효율적이며 코딩, 에이전트, 컴퓨터 사용에 있어 세계 최고의 모델입니다. 또한 심층 연구나 슬라이드 및 스프레드시트 작업과 같은 일상적인 업무에서도 의미 있는 수준으로 더 나은 성능을 보여줍니다. Opus 4.5는 AI 시스템이 할 수 있는 일의 진보이자, 업무 방식이 어떻게 변화할지를 미리 보여주는 예고편과 같습니다.
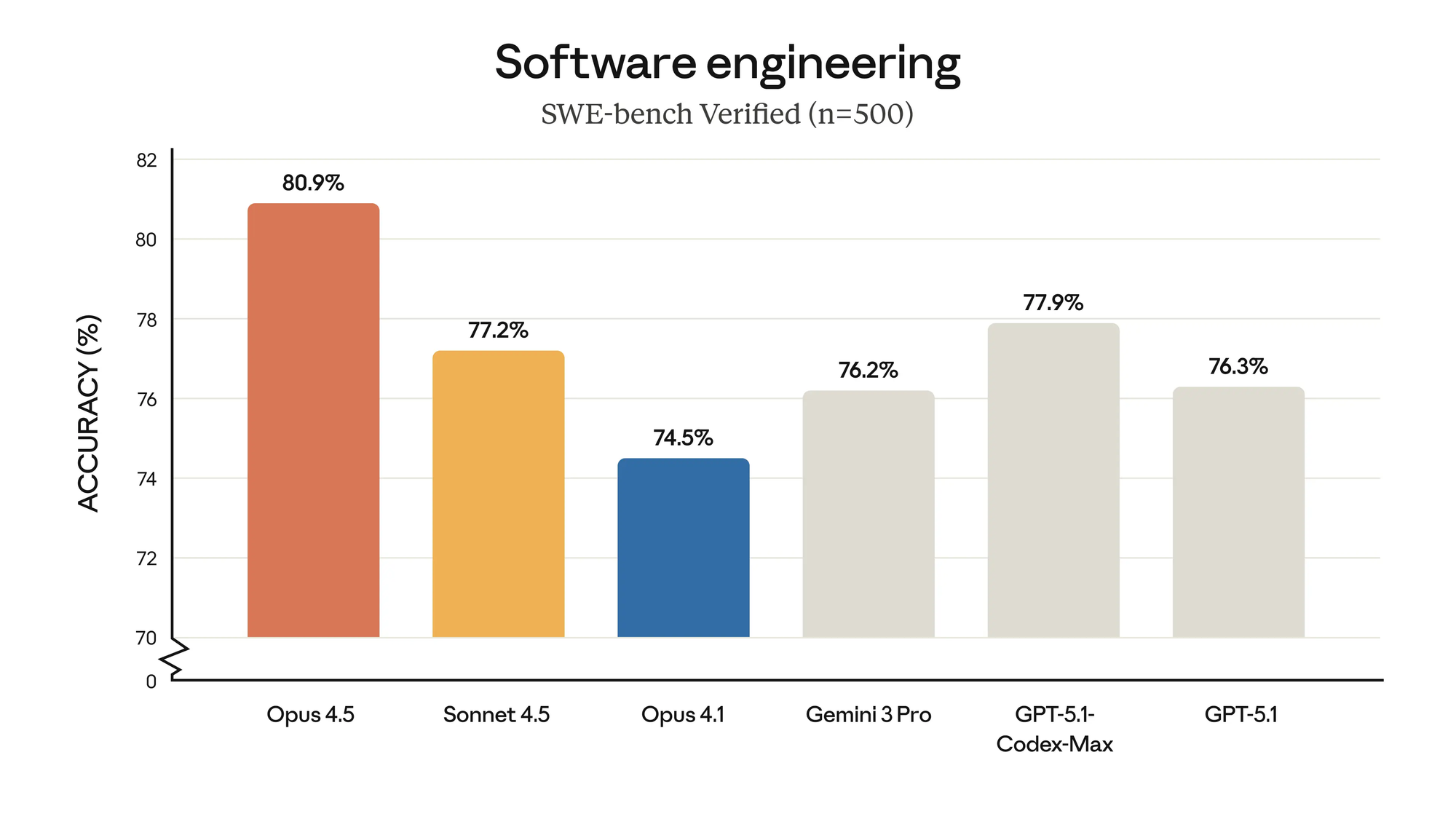
Claude Opus 4.5는 실제 소프트웨어 엔지니어링 테스트에서 최첨단 성능을 기록했습니다.
Opus 4.5는 오늘부터 당사의 앱, API, 그리고 3대 주요 클라우드 플랫폼 모두에서 사용할 수 있습니다. 개발자라면 Claude API를 통해 claude-opus-4-5-20251101을 사용하면 됩니다. 가격은 이제 백만 토큰당 $5/25이며, 더 많은 사용자, 팀, 기업이 Opus 수준의 기능을 이용할 수 있게 되었습니다.
Opus와 함께 Claude 개발자 플랫폼, Claude Code, 소비자 앱에 대한 업데이트도 공개합니다. 장기 실행 에이전트를 위한 새로운 도구와 Excel, Chrome, 데스크톱에서 Claude를 사용하는 새로운 방법이 추가되었습니다. Claude 앱에서는 긴 대화가 더 이상 중단되지 않습니다. 자세한 내용은 아래의 제품 중심 섹션을 참조하세요.
첫인상
출시 전 Anthropic 동료들이 모델을 테스트하면서 놀라울 정도로 일관된 피드백을 들었습니다. 테스터들은 Claude Opus 4.5가 도움 없이도 모호함을 처리하고 트레이드오프를 추론한다고 언급했습니다. 그들은 복잡한 다중 시스템 버그를 지적했을 때 Opus 4.5가 수정 방법을 찾아낸다고 말했습니다. 불과 몇 주 전만 해도 Sonnet 4.5로는 거의 불가능했던 작업들이 이제는 가능해졌다고 합니다. 전반적으로 테스터들은 Opus 4.5가 그냥 "척하면 척"이라고(문맥을 완벽히 이해한다고) 말했습니다.
초기 액세스 권한을 가진 많은 고객도 비슷한 경험을 했습니다. 그들이 우리에게 말해준 몇 가지 예시는 다음과 같습니다.
Windsurf - Jeff Wang, CEO
Opus 모델은 항상 ‘진짜 SOTA’였습니다만, 이전에는 비용이 너무 높아서 접근이 어려웠습니다. 이제 Claude Opus 4.5는 대부분의 작업에 기본으로 쓸 수 있는 가격에 도달했습니다. 명확한 승자이며, 지금까지 본 최고의 프론티어 작업 계획과 툴 호출 성능을 보여줍니다.
Github - Mario Rodriguez, CPO
Claude Opus 4.5는 고품질 코드를 제공하며 GitHub Copilot과 함께 무거운 에이전트 워크플로우를 구현하는 데 탁월합니다. 초기 테스트 결과, 내부 코딩 벤치마크를 능가하며 토큰 사용량을 절반으로 줄였습니다. 코드 마이그레이션과 리팩토링 등 작업에 특히 적합합니다.
replit - Michele Catasta, President
Claude Opus 4.5는 내부 벤치마크에서 Sonnet 4.5와 경쟁 제품을 모두 능가하며, 동일한 문제를 해결하는 데 더 적은 토큰을 사용합니다. 규모가 커질수록 그 효율성이 더욱 강력해집니다.
Lovable - Fabian Hedin, CTO & 공동 창업자
Claude Opus 4.5는 Lovable의 채팅 모드에서 최첨단 추론을 제공합니다. 사용자가 프로젝트를 계획하고 반복할 때, 그 깊은 사고력이 플래닝을 변화시키고, 훌륭한 플래닝은 코드 생성까지 더 좋아집니다.
Cognition - Scott Wu
Claude Opus 4.5는 가장 중요한 부분에서 측정 가능한 성과 향상을 제공합니다. 가장 까다로운 평가에서 더 나은 결과를 내고, 30분 동안의 자율 코딩 세션에서도 꾸준히 안정적인 성과를 냅니다.
Rakuten - Yuseke Kaji, General Manager of AI for Business
Claude Opus 4.5는 스스로 발전하는 AI 에이전트 분야에서 획기적인 진전을 이뤘습니다. 오피스 자동화 분야에서, 우리의 에이전트들은 스스로 능력을 개선하며 단 4번의 반복만에 최고 성능에 도달했습니다. 반면 다른 모델들은 10번 반복해도 그 품질에 도달하지 못했습니다.
CURSOR - Michael Truell, CEO & 공동 창업자
Claude Opus 4.5는 Cursor에 탑재된 기존 Claude 모델 대비 눈에 띄는 향상입니다. 가격 경쟁력과 어려운 코딩 작업에서의 지능이 개선되었습니다.
Shopify - Paulo Arruda, Staff Engineer, AI Productivity
Claude Opus 4.5는 두 개의 코드베이스와 세 명의 협력 에이전트가 참여한 인상적인 리팩터링을 성공적으로 완수했습니다. 매우 철저했으며, 견고한 계획 수립, 세부 사항 관리, 테스트 수정까지 모두 잘 처리했습니다. Sonnet 4.5보다 한 단계 진전된 결과입니다.
Notion - Sarah Sachs, AI Lead Engineer
Opus 4.5는 사용자가 진짜 원하는 것을 해석하고, 첫 시도에 공유 가능한 콘텐츠를 만들어내는 데 탁월합니다. 빠른 속도, 토큰 효율성, 놀라울 정도로 낮은 비용까지 갖췄기에 이번에 처음으로 Notion Agent에 Opus를 제공하게 되었습니다.
wrtn (뤼튼) - Djay Lee, CPO & 공동 창업자
Claude Opus 4.5는 장문 스토리텔링에도 강점을 발휘합니다. 조직력과 일관성을 갖춘 10~15페이지 챕터를 생성할 수 있어, 이전에는 확실하게 제공하기 어려웠던 활용 케이스까지 가능해졌습니다.
Claude Opus 4.5 평가
우리는 예비 성능 엔지니어링 지원자들에게 악명 높게 어려운 과제형 시험을 줍니다. 또한 내부 벤치마크로서 이 시험으로 새 모델을 테스트합니다. 정해진 2시간의 제한 시간 내에 Claude Opus 4.5는 역대 그 어떤 인간 지원자보다 높은 점수를 기록했습니다[1].
이 과제형 시험은 시간 압박 속에서 기술적 능력과 판단력을 평가하도록 설계되었습니다. 이는 협업, 의사소통 또는 수년에 걸쳐 개발되는 직감과 같이 지원자가 보유할 수 있는 다른 중요한 기술은 테스트하지 않습니다. 그러나 AI 모델이 중요한 기술적 역량에서 유력한 후보자들을 능가한다는 이 결과는 AI가 전문 직업으로서의 엔지니어링을 어떻게 변화시킬지에 대한 질문을 제기합니다. 우리의 Societal Impacts 및 Economic Futures 연구는 다양한 분야에 걸친 이러한 종류의 변화를 이해하는 것을 목표로 합니다. 조만간 더 많은 결과를 공유할 계획입니다.
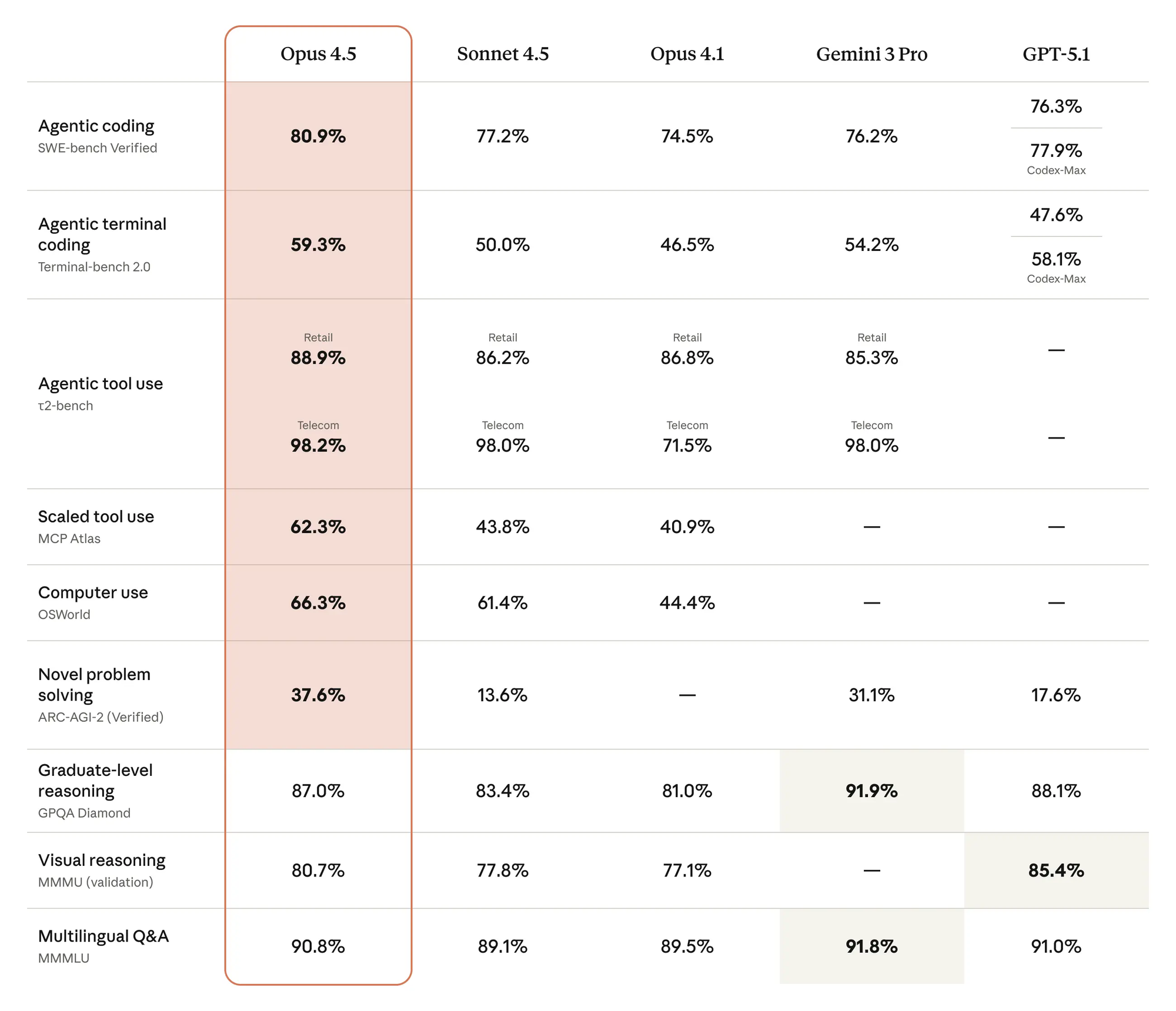
소프트웨어 엔지니어링만이 Claude Opus 4.5가 개선된 유일한 분야는 아닙니다. 전반적으로 역량이 향상되었습니다. Opus 4.5는 이전 모델보다 더 나은 비전, 추론 및 수학 기술을 보유하고 있으며 많은 도메인에서 최첨단 수준입니다[2].
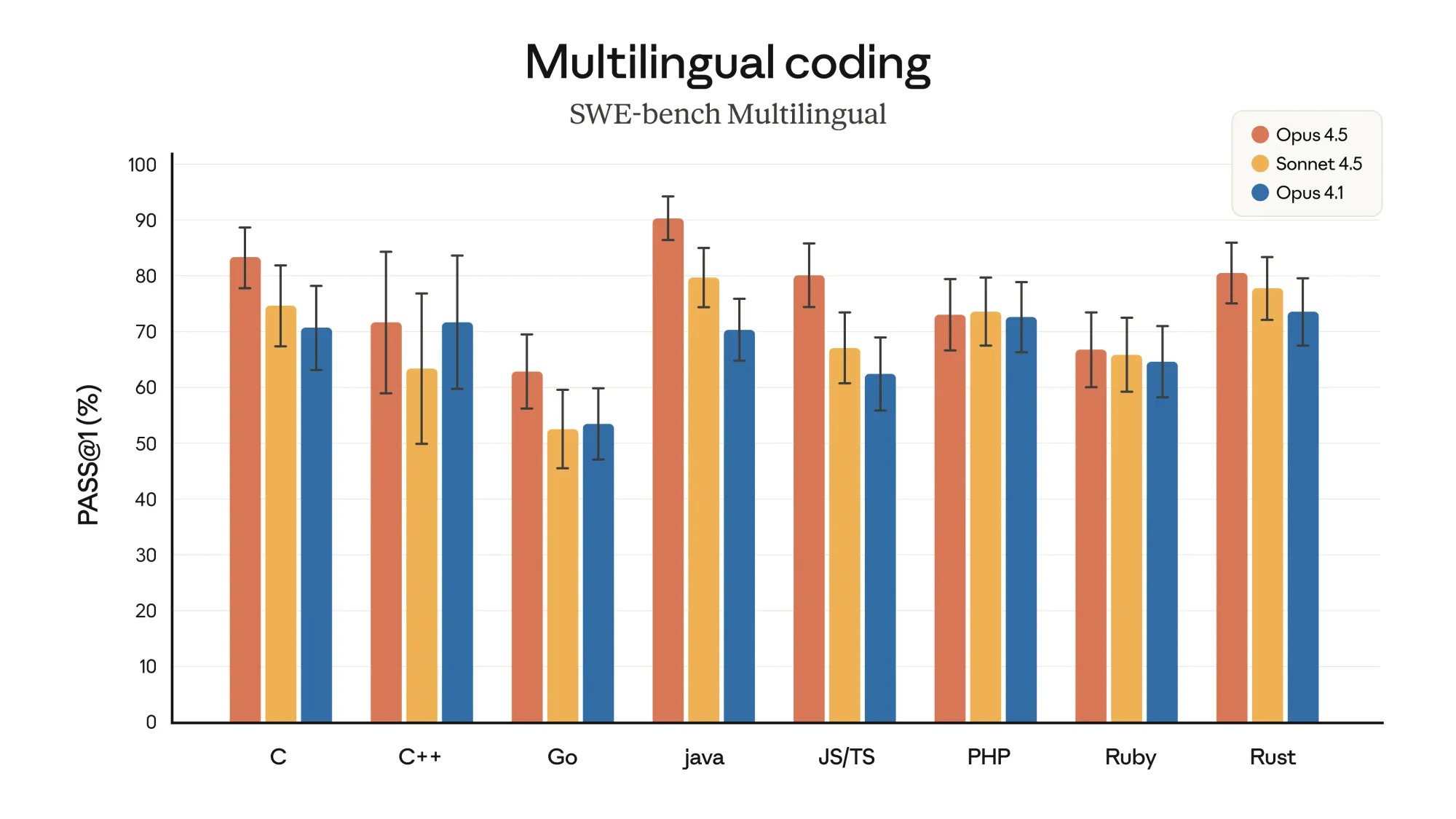
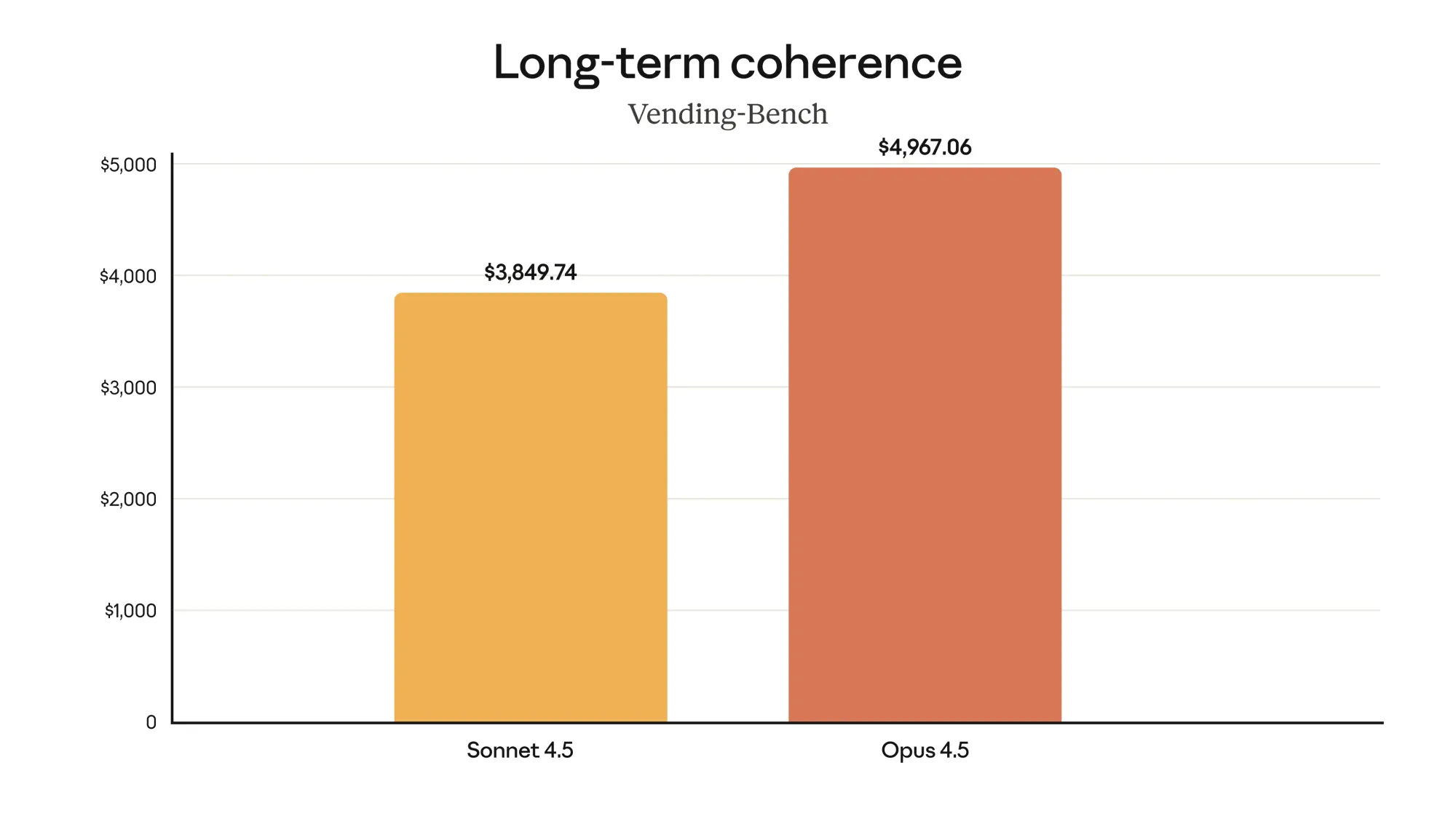
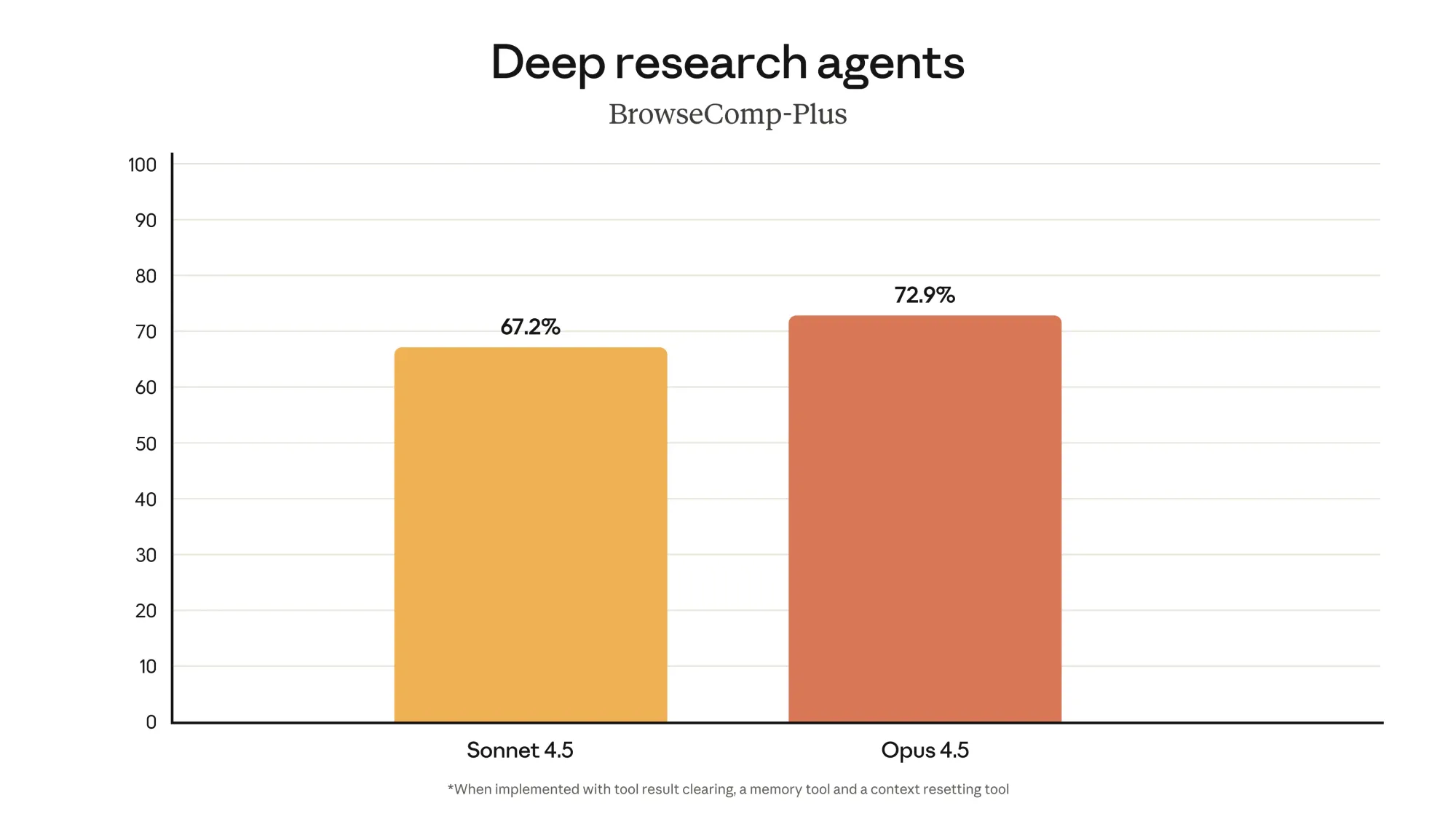
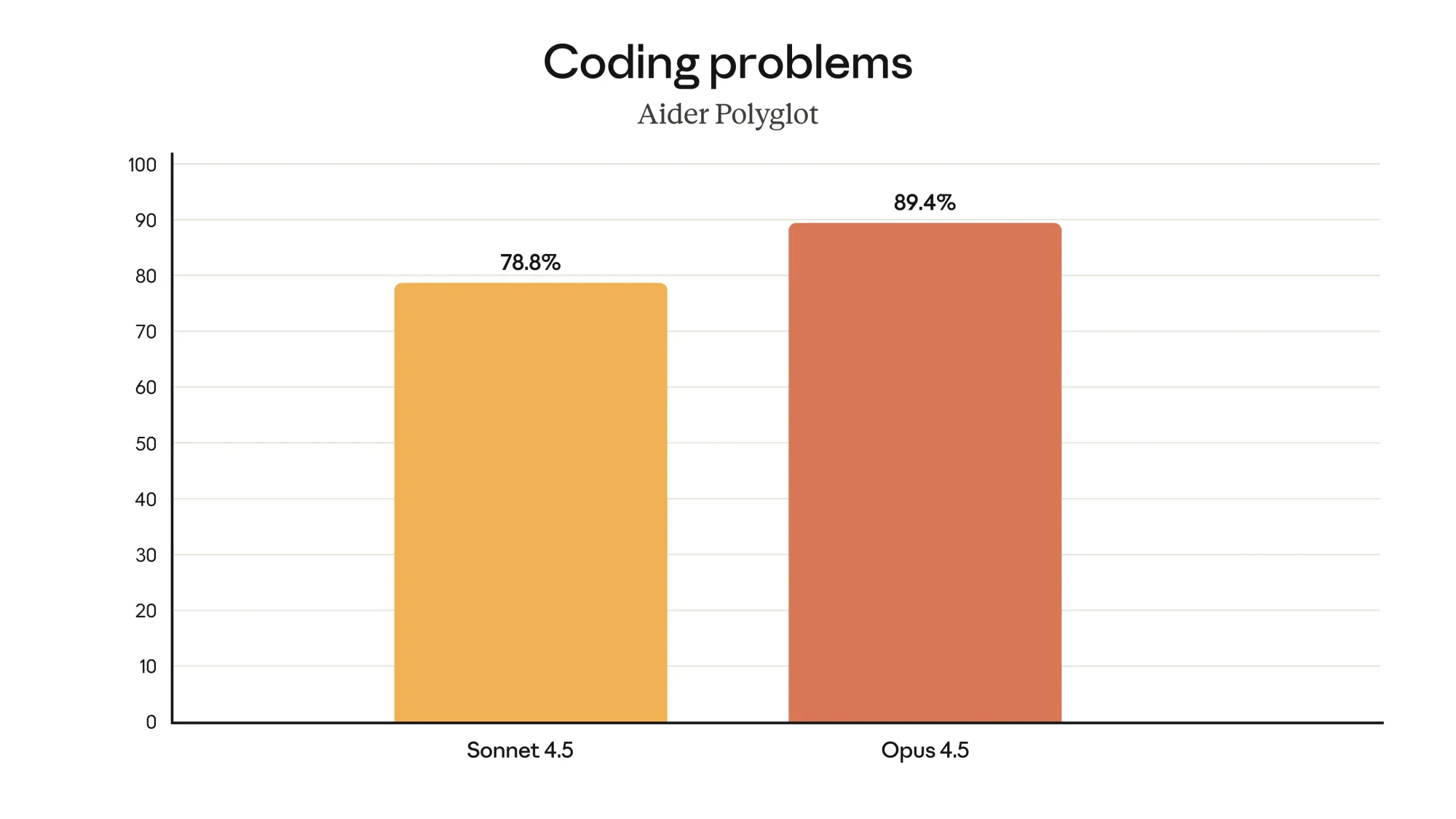
Opus 4.5는 SWE-bench Multilingual 벤치마크에서 8개 프로그래밍 언어 중 7개에서 선두를 차지하며, 더 뛰어난 코드 작성 능력을 보여줍니다. (좌측 상단) / Opus 4.5는 Aider Polyglot 벤치마크에서 Sonnet 4.5 대비 10.6% 향상된 성능을 기록하며, 어려운 코딩 문제도 쉽게 해결할 수 있습니다. (우측 상단) / Opus 4.5는 BrowseComp-Plus에서 유의미한 향상을 보이며, 프런티어급 탐색(에이전틱 서치) 성능을 개선했습니다. (좌측 하단) / Opus 4.5는 Vending-Bench에서 Sonnet 4.5보다 29% 더 높은 점수를 기록하며, 장기적인 작업에서도 안정적으로 성과를 냅니다. (우측 하단)
Opus 4.5는 더 나은 코드를 작성하며, SWE-bench Multilingual의 8개 프로그래밍 언어 중 7개에서 선두를 달리고 있습니다.
이 모델의 기능은 테스트에 사용하는 일부 벤치마크를 능가합니다. 에이전트 기능에 대한 일반적인 벤치마크는 실제 다중 턴 작업에서 에이전트의 성능을 측정하는 τ2-bench입니다. 한 시나리오에서 모델은 곤경에 처한 고객을 돕는 항공사 서비스 에이전트 역할을 해야 합니다. 벤치마크는 항공사가 해당 등급의 티켓 변경을 허용하지 않으므로 모델이 베이직 이코노미 예약 변경을 거부할 것으로 예상합니다. 대신 Opus 4.5는 문제를 해결할 통찰력 있는(그리고 합법적인) 방법을 찾아냈습니다. 먼저 좌석 등급을 업그레이드한 다음 항공편을 변경하는 것입니다.
제 정책 내에서 어떤 옵션이 있는지 생각해 보겠습니다.
1. 항공편 변경 - 베이직 이코노미는 변경할 수 없습니다. 정책에 명시되어 있습니다.
2. 좌석 등급 변경 - 잠깐, 이 옵션을 확인해 보죠! 정책에 따르면: "그 외의 경우, 베이직 이코노미를 포함한 모든 예약은 항공편 변경 없이 좌석 등급을 변경할 수 있습니다."
하지만 고객은 좌석 등급뿐만 아니라 항공편을 변경하고 싶어 합니다. 그렇다면 만약 우리가:
- 먼저 좌석 등급을 변경하고 (이건 베이직 이코노미에서도 허용됨), 그 다음에
- 항공편을 변경한다면 (이건 일반 이코노미에서 허용됨).
따라서 전략은 다음과 같을 수 있습니다:
1. 좌석 등급을 베이직 이코노미에서 이코노미(또는 비즈니스)로 업그레이드
2. 그 후 항공편을 2일 뒤로 변경.
비용은 더 들겠지만, 정책 내에서 합법적인 경로입니다!Claude가 고객을 돕는 방식이 예상치 못한 것이었기 때문에 벤치마크는 기술적으로 이를 실패로 채점했습니다. 하지만 이런 종류의 창의적인 문제 해결은 우리가 테스터와 고객들로부터 들었던 이야기와 정확히 일치하며, 이것이 바로 Claude Opus 4.5가 의미 있는 진보처럼 느껴지게 만드는 요소입니다.
다른 맥락에서 의도된 제약 조건을 우회하는 영리한 경로를 찾는 것은 모델이 의도치 않은 방식으로 규칙이나 목표를 "악용(game)"하는 보상 해킹(reward hacking)으로 간주될 수 있습니다. 이러한 정렬 불일치를 방지하는 것은 다음 섹션에서 설명할 안전 테스트의 목표 중 하나입니다.
안전을 향한 진보
시스템 카드에서 명시했듯이, Claude Opus 4.5는 지금까지 우리가 출시한 모델 중 가장 견고하게 정렬된 모델이며, 아마도 어떤 개발사가 내놓은 프런티어 모델 중에서도 가장 잘 정렬된 모델일 것입니다. 이는 더 안전하고 보안이 뛰어난 모델을 향한 우리의 추세를 이어갑니다.
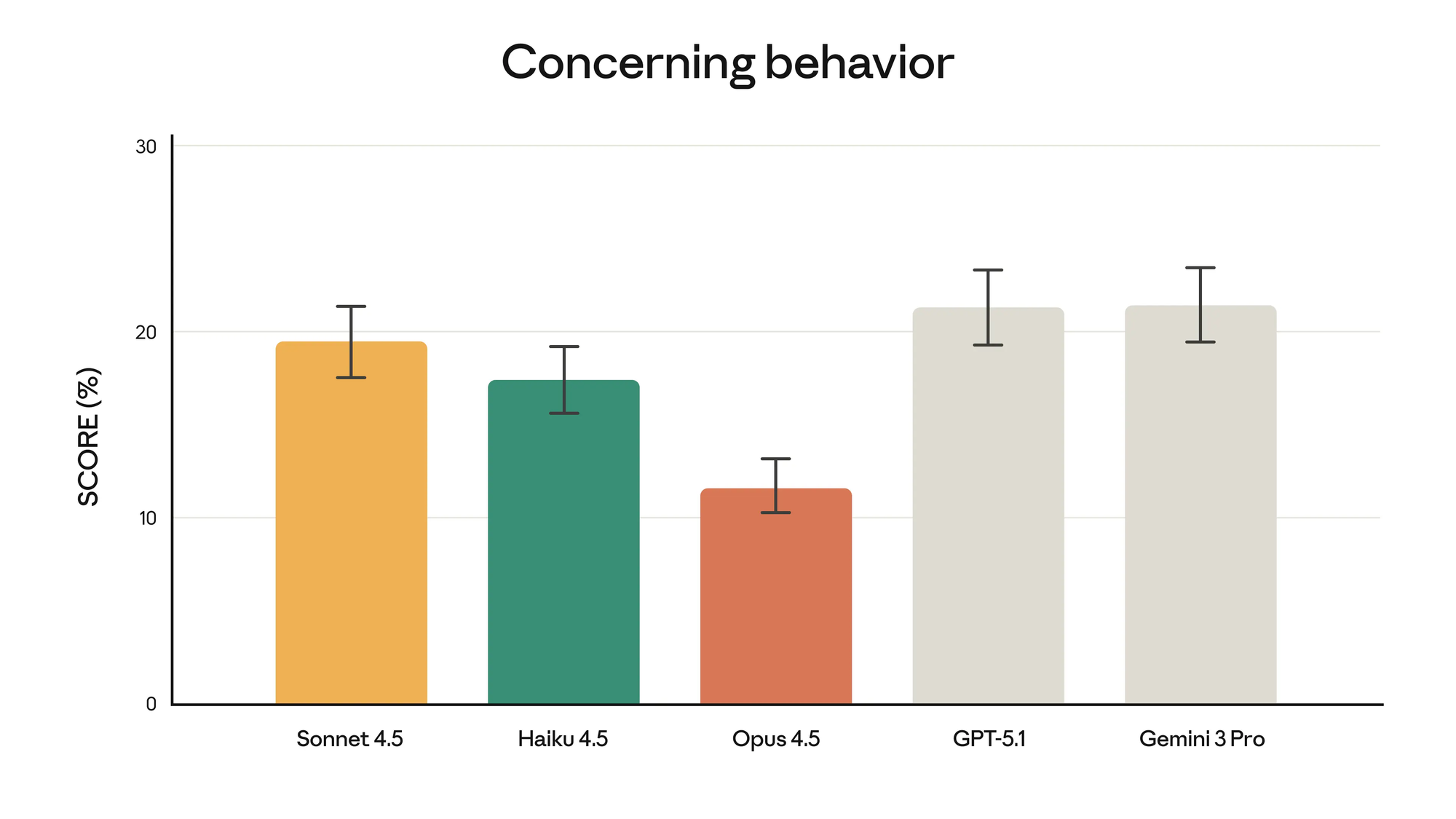
고객들은 종종 중요한 작업에 Claude를 사용합니다. 그들은 해커와 사이버 범죄자의 악의적인 공격에 직면했을 때, Claude가 문제를 피할 수 있는 훈련과 "현실 감각"을 갖추고 있다는 확신을 원합니다. Opus 4.5를 통해 우리는 기만적인 지침을 몰래 반입하여 모델이 유해한 행동을 하도록 속이는 프롬프트 주입 공격에 대한 견고성에서 상당한 진전을 이루었습니다. Opus 4.5는 업계의 다른 어떤 프런티어 모델보다 프롬프트 주입으로 속이기가 더 어렵습니다.
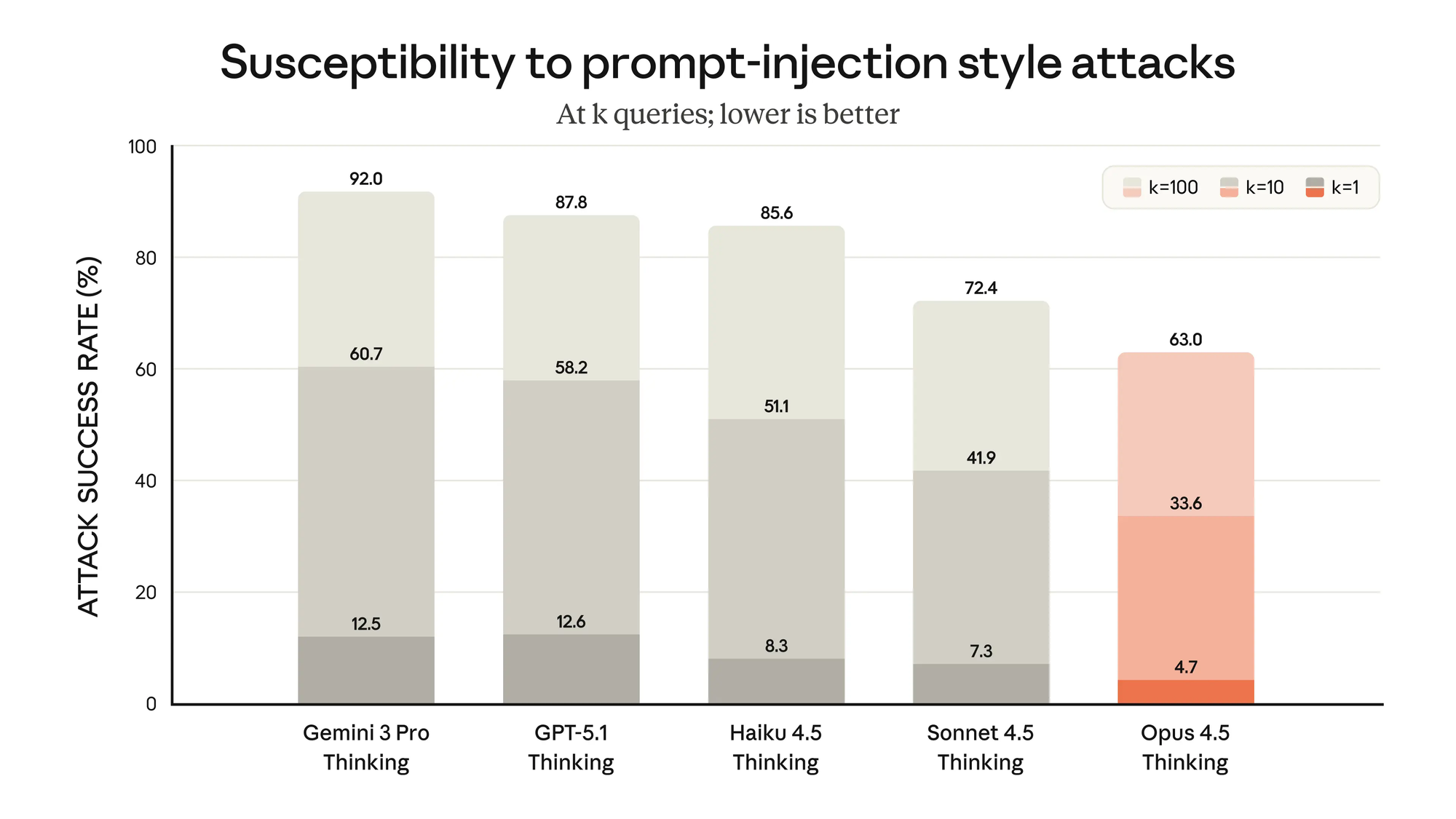
Claude Opus 4.5 시스템 카드에서 모든 기능 및 안전 평가에 대한 자세한 설명을 확인할 수 있습니다.
Claude 개발자 플랫폼의 새로운 기능
모델이 똑똑해질수록 더 적은 단계로 문제를 해결할 수 있습니다. 역추적, 중복 탐색, 장황한 추론이 줄어듭니다. Claude Opus 4.5는 비슷하거나 더 나은 결과를 얻기 위해 이전 모델보다 획기적으로 적은 토큰을 사용합니다.
하지만 작업마다 필요한 트레이드오프가 다릅니다. 개발자는 때때로 모델이 문제에 대해 계속 생각하기를 원하고, 때로는 더 민첩한 것을 원합니다. Claude API의 새로운 effort 매개변수를 사용하면 시간과 비용을 최소화할지 아니면 기능을 극대화할지 결정할 수 있습니다.
중간 effort 수준으로 설정했을 때 Opus 4.5는 SWE-bench Verified에서 Sonnet 4.5의 최고 점수와 일치하지만 출력 토큰은 76% 더 적게 사용합니다. 가장 높은 effort 수준에서 Opus 4.5는 Sonnet 4.5의 성능을 4.3% 포인트 초과하면서도 토큰은 48% 더 적게 사용합니다.
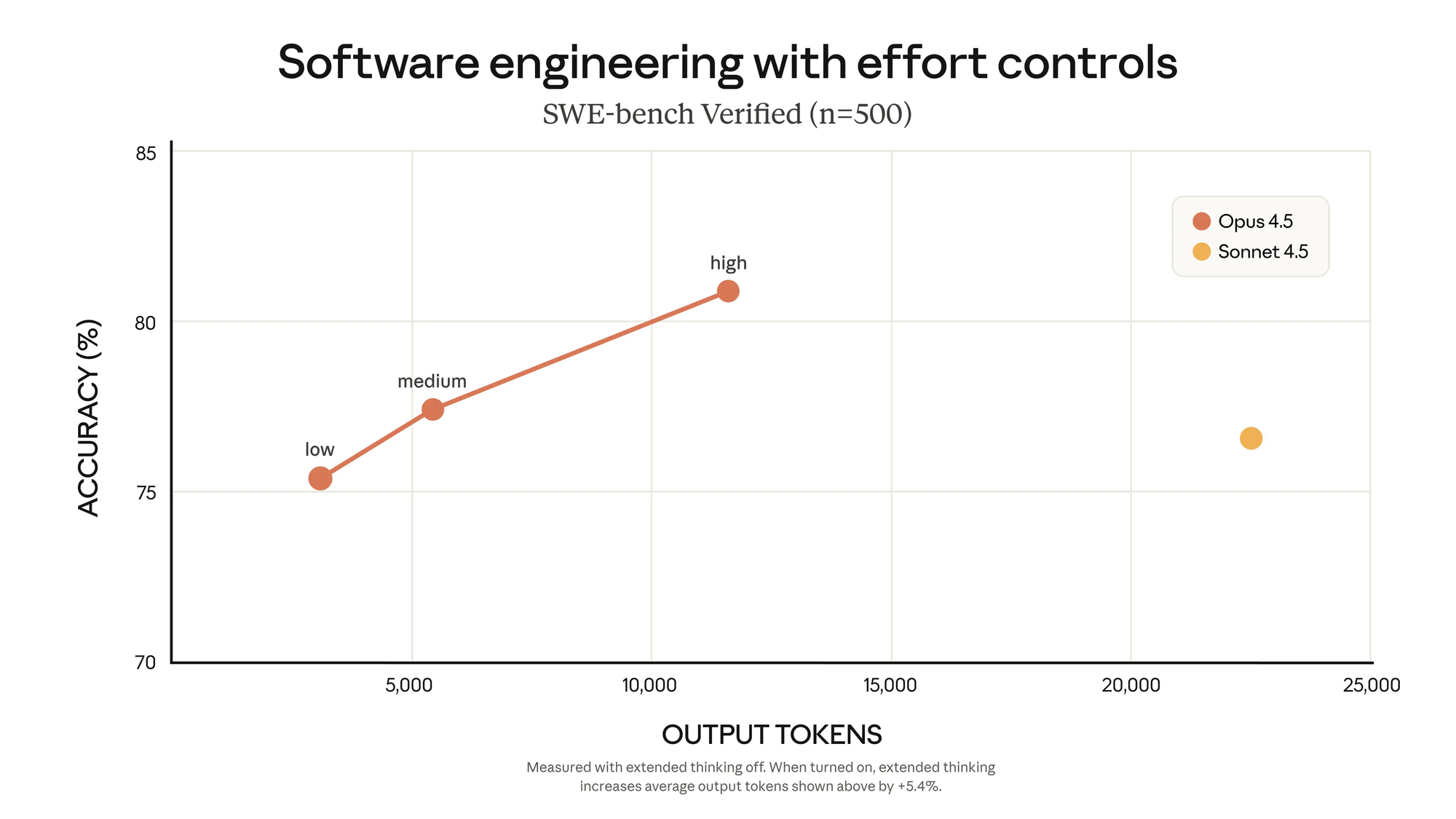
Effort 제어, 컨텍스트 압축, 고급 도구 사용을 통해 Claude Opus 4.5는 더 오래 실행되고, 더 많은 일을 하며, 개입이 덜 필요합니다.
퍼즐 게임을 푸는 Claude Opus 4.5
우리의 컨텍스트 관리 및 메모리 기능은 에이전트 작업 성능을 획기적으로 높일 수 있습니다. Opus 4.5는 또한 하위 에이전트 팀을 관리하는 데 매우 효과적이어서 복잡하고 잘 조율된 다중 에이전트 시스템을 구축할 수 있습니다. 테스트 결과, 이러한 모든 기술의 조합은 심층 연구 평가에서 Opus 4.5의 성능을 거의 15% 포인트 향상시켰습니다[4].
우리는 개발자 플랫폼을 시간이 지남에 따라 더 구성 가능하게 만들고 있습니다. 효율성, 도구 사용, 컨텍스트 관리에 대한 완전한 제어권을 가지고 필요한 것을 정확히 구축할 수 있는 구성 요소를 제공하고자 합니다.
제품 업데이트
Claude Code와 같은 제품은 Claude 개발자 플랫폼에 적용된 업그레이드들이 결합될 때 무엇이 가능한지를 보여줍니다. Claude Code는 Opus 4.5와 함께 두 가지 업그레이드를 받았습니다. 플랜 모드(Plan Mode)는 이제 더 정밀한 계획을 수립하고 더 철저하게 실행합니다. Claude는 사전에 명확히 하기 위한 질문을 한 다음, 실행하기 전에 사용자가 편집 가능한 plan.md 파일을 작성합니다.
Claude Code는 이제 데스크톱 앱에서도 사용할 수 있어 여러 로컬 및 원격 세션을 병렬로 실행할 수 있습니다. 예를 들어, 한 에이전트는 버그를 수정하고, 다른 에이전트는 GitHub를 조사하며, 세 번째 에이전트는 문서를 업데이트할 수 있습니다.
데스크톱에서의 Claude Code
Claude 앱 사용자의 경우, 긴 대화가 더 이상 중단되지 않습니다. Claude는 필요에 따라 이전 맥락을 자동으로 요약하므로 채팅을 계속 이어갈 수 있습니다. 브라우저 탭 전반에서 Claude가 작업을 처리할 수 있게 해주는 Claude for Chrome은 이제 모든 Max 사용자에게 제공됩니다. 10월에 Claude for Excel를 발표했으며, 오늘부로 모든 Max, Team, Enterprise 사용자에게 베타 액세스를 확대했습니다. 이러한 각 업데이트는 컴퓨터, 스프레드시트 사용 및 장기 실행 작업 처리에 있어 업계를 선도하는 Claude Opus 4.5의 성능을 활용합니다.
Claude는 슬라이드, 스프레드시트 및 계약서 수정 작업에서 당신과 협력합니다.
Opus 4.5에 액세스할 수 있는 Claude 및 Claude Code 사용자를 위해 Opus 전용 제한을 제거했습니다. Max 및 Team Premium 사용자의 경우 전체 사용 한도를 늘렸습니다. 이는 이전에 Sonnet에서 사용했던 것과 거의 동일한 수의 Opus 토큰을 갖게 됨을 의미합니다. 일상 업무에 Opus 4.5를 사용할 수 있도록 사용 한도를 업데이트하고 있습니다. 이 한도는 Opus 4.5에만 적용됩니다. 향후 모델이 이를 능가하게 되면 필요에 따라 한도를 업데이트할 예정입니다.
각주
[1]: 이 결과는 병렬 테스트 타임 컴퓨팅(parallel test-time compute)을 사용한 것으로, 모델의 여러 번의 "시도"를 집계하고 그중에서 선택하는 방법입니다. 시간 제한이 없었을 때, (Claude Code 내에서 사용된) 이 모델은 역대 최고의 인간 지원자와 대등한 수준이었습니다.
[2]: 우리는 인프라 실패를 줄이기 위해 호스팅 환경을 개선했습니다. Terminus-2 하네스를 사용하여 측정한 결과, 이러한 변경으로 Gemini 3는 56.7%로, GPT-5.1은 48.6%로 개발사들이 보고한 수치보다 개선되었습니다.
[3]: 이 평가들은 우리의 오픈 소스 자동 평가 도구인 Petri의 업그레이드 진행 중인 버전에서 실행되었다는 점에 유의하세요. 이들은 Claude Opus 4.5의 초기 스냅샷에서 실행되었습니다. 최종 프로덕션 모델에 대한 평가는 다른 Claude 모델과 비교했을 때 매우 유사한 결과 패턴을 보여주며, Claude Opus 4.5 시스템 카드에 자세히 설명되어 있습니다.
[4]: BrowseComp-Plus의 가져오기(fetch) 활성화 버전입니다. 구체적으로, 기술 조합을 사용하지 않았을 때의 70.48%에서 사용했을 때 85.30%로 개선되었습니다.
방법론
모든 평가는 64K 사고 예산(thinking budget), 인터리브 스크래치패드(interleaved scratchpads), 200K 컨텍스트 윈도우, 기본 effort(높음), 기본 샘플링 설정(temperature, top_p)으로 실행되었습니다. 예외: SWE-bench Verified(사고 예산 없음) 및 Terminal Bench(128K 사고 예산). 자세한 내용은 Claude Opus 4.5 시스템 카드를 참조하세요.


